JavaScript rendering issues I would fix on TripAndThrill.com
18th June, 2025
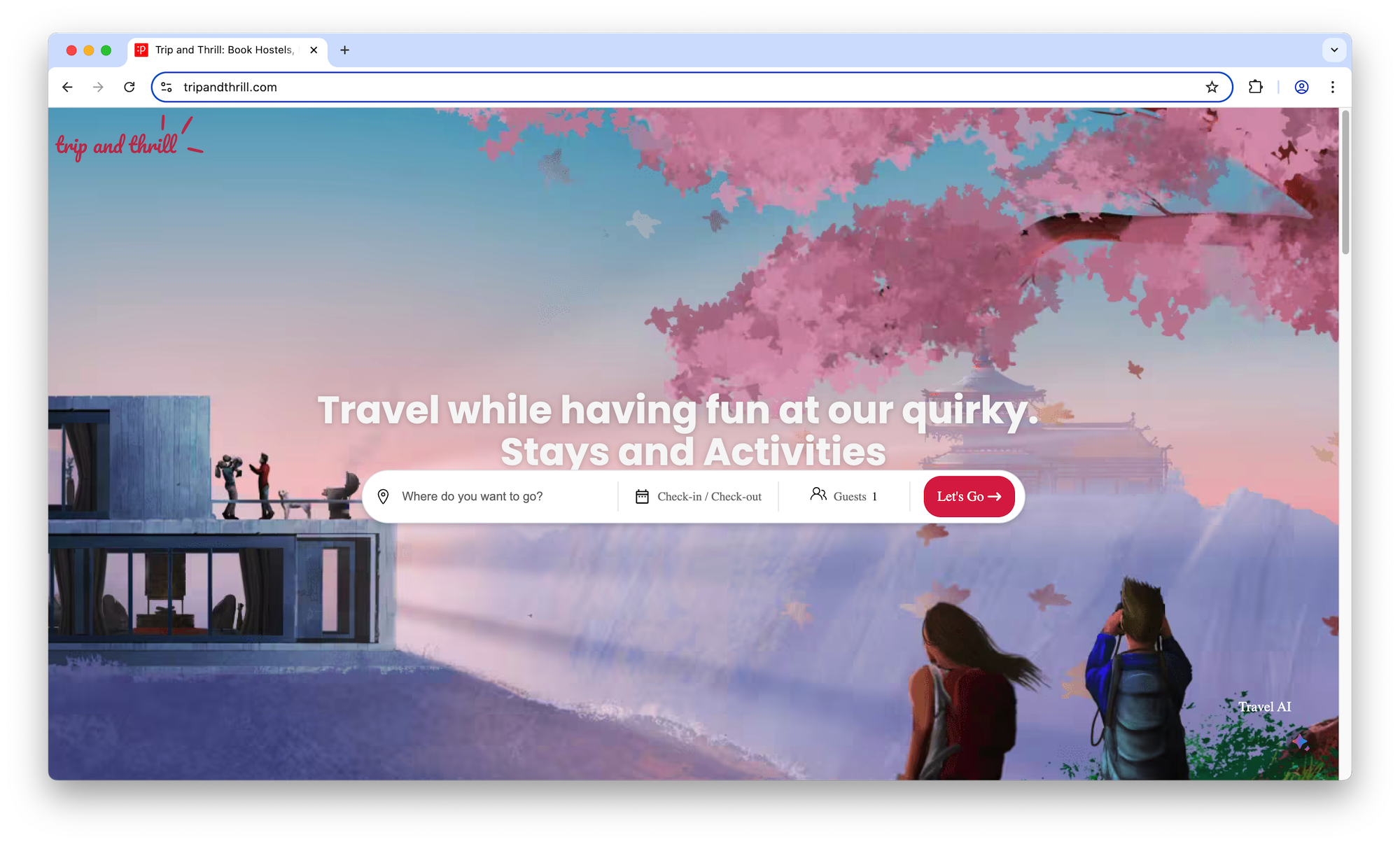
TripAndThrill.com lists hostels, homestays and events in various travel-worthy destinations across India.
- The main website is built with React.
- They have a blog at blogs.tripandthrill.com which seems to be a custom site (not based on any JavaScript frontend framework).
The blogs website does not seem to have any of the JavaScript rendering issues seen with the main website (detailed in the sections below). I’m not sure, but this could be one of the reasons why more blog URLs appear Google indexed than the main site URLs.
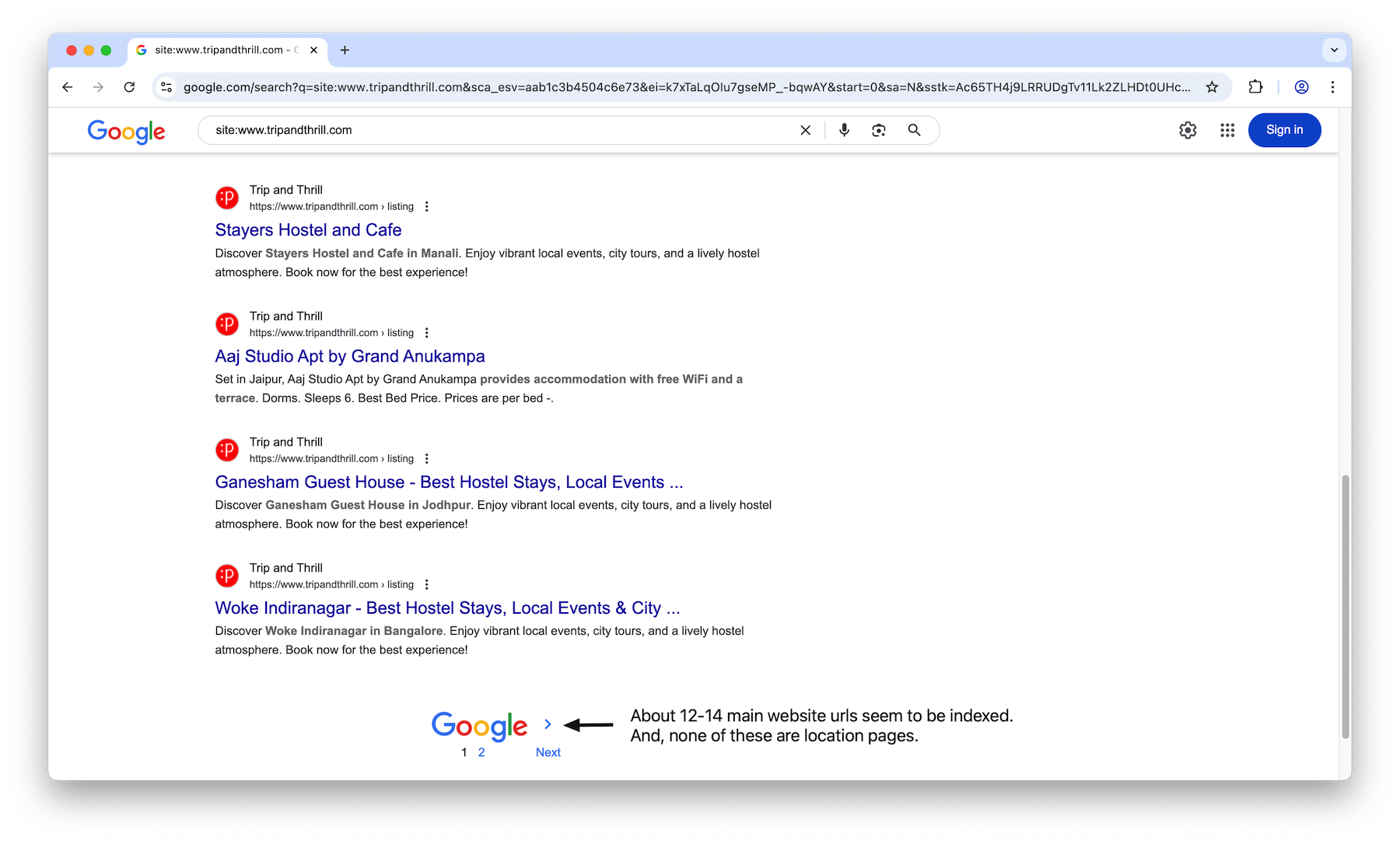
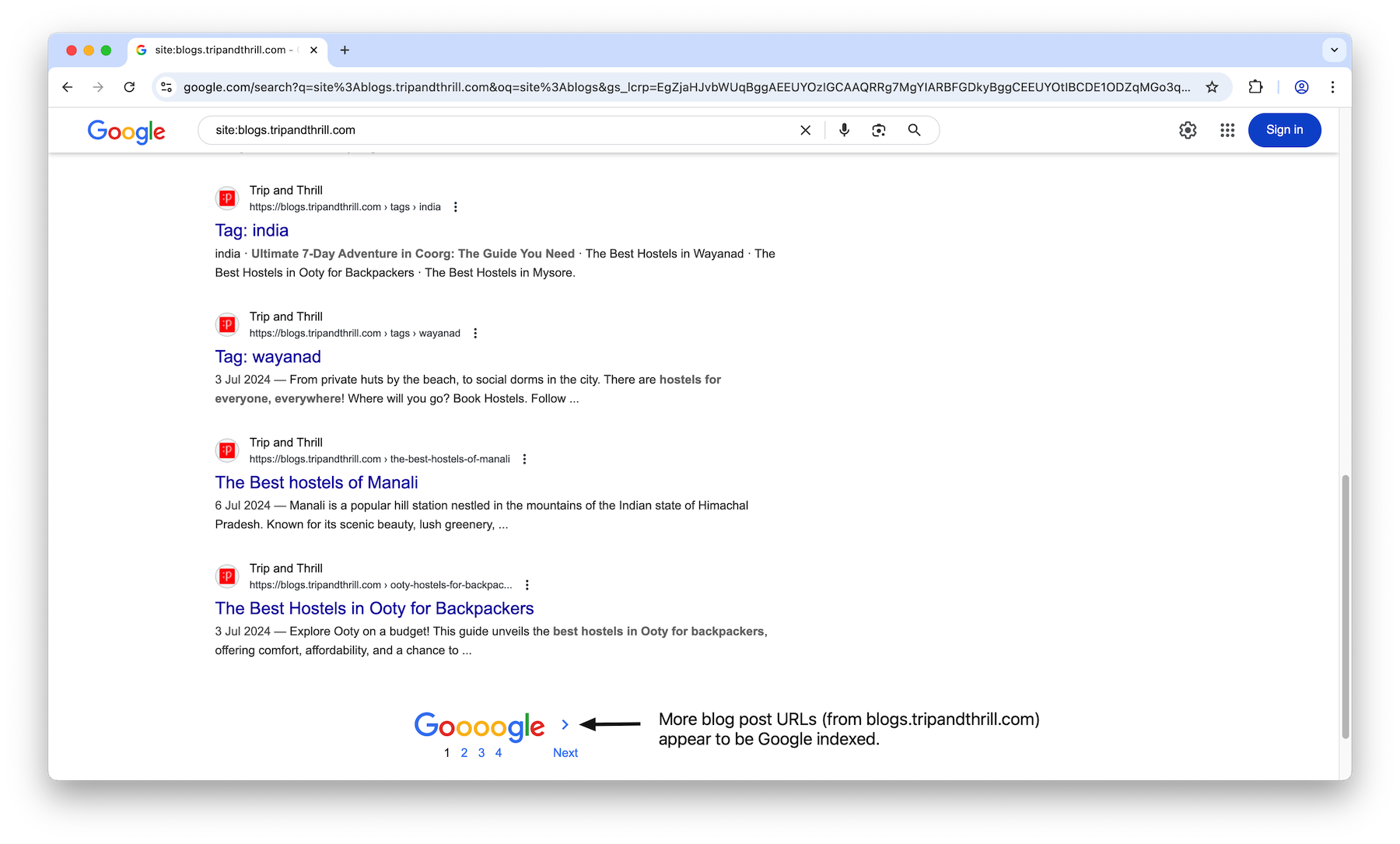
With that, let us dig into the JavaScript rendering issues on the main React based website.
Links on the main website
The HTML returned from the server for their homepage, listing pages and product detail pages contains zero anchor links.

This would mean that sitemap would potentially be the only way for search crawlers to discover the pages during the initial crawl phase.
Once the page is rendered on the browser-side, all the navigation links to the various listing pages is built using <div> with onClick JavaScript. As a result, the crawlers would not identify these as navigation links and would not navigate to the various pages via on-page links.

To ensure that crawlers identify the navigation links to traverse the various on-page links, I would change the website navigation to <a href="..." /> instead of the currently used JavaScript driven onClick events. However, using <a href="..." /> within React JSX triggers a full-page refresh for actual visitors when they navigate around the website. This can be slower than browser-side route change for the users already on the website. So, to handle this correctly, I would use the following approach (depending on the frontend routing library in use):
// With Next.js, the Link component handles creating
// semantic links alongside providing client-side routing experience
import Link from 'next/link';
<Link href="/homestays">
<div className="card">
<h2>Homestays</h2>
<p>Check out our list of Homestays</p>
</div>
</Link>
// The Link component within `react-router-dom` also creates
// anchor links underneath while also providing client-side routing experience
import { Link } from 'react-router-dom';
<Link to="/homestays"><div className="card">
<h2>Homestays</h2>
<p>Check out our list of Homestays</p>
</div>
</Link>
Since this website appears to be using React along with React Router, using react-router-dom as above would
- ensure semantic anchor links for navigation
- ensure seemless navigation experience without full-page reload for on-site users as they navigate between pages
The two libraries mentioned above also provide dynamic routing capabilities via router.push('/homestays') with Next.js or navigate('/homestays') with react-router-dom. These DO NOT translate into semantic links. As a result, I would use these only for programmatic actions (form submission, dynamic event handling, etc) and not for navigation between pages.
Server-side rendering of content
The body of the HTML returned by the server for all the pages on the main website is empty.

This means only those crawlers would access the page content that can execute the browser-side JavaScript. One reason the data isn’t rendered on the server-side is because the fetching of the data that needs to be displayed from the APIs is done within the useEffect hook:

useEffect for a component only executes after the component has been mounted to the DOM. And, since DOM doesn’t exist on the server-side - any code within useEffect never executes on the server-side.
Now, one way to achieve Server-side rendering would be to use a React framework like Next.js or Remix that supports SSR. But, since this website appears to be using React, we can use react-dom/server along with express to achieve Server-side rendering.
Below is my server.js that would be the entry point to server-side rendering running on the server.
// Generate HTML on the server-side via react-dom/server method renderToString
// instead of sending an empty <div id="root"></div> to the browser
import express from "express";
import { renderToString } from "react-dom/server";
import { StaticRouterProvider, createStaticHandler, createStaticRouter } from "react-router-dom/server";
import { routes } from "./routes";
const app = express();
const handler = createStaticHandler(routes);
app.use("*", async (req, res) => {
const context = await handler.query(req.originalUrl);
const router = createStaticRouter(handler.dataRoutes, context);
const html = renderToString(
<StaticRouterProvider
router={router}
context={context}
/>
);
res.send(`
<!DOCTYPE html>
<html>
<body><div id="root">${html}</div></body>
</html>
`);
});
app.listen(8000, () => console.log("Server started on http://localhost:8000"));
Below is my routes.js that the above server.js uses to determine the matching route. Note that none of the data-fetching can be within the components. Instead, it needs to be in separate functions referenced within the routes.js file.
// Use `createRoutesFromElements` from react-router-dom which provides a loader
// parameter which can contain data-fetching part. This would execute on the
// server-side for requests coming to the server and on the browser-side for
// routes navigated on the browser.
import { createRoutesFromElements, Route } from "react-router-dom";
import Home from "./pages/Home";
import Listing from "./pages/Listing";
export const routes = createRoutesFromElements(
<>
<Route path="/" element={<Home />} />
<Route
path="/city/:slug"
element={<Listing />}
loader={async ({ params }) => {
const res = await fetch(`https://apibaseurl.com/cities/${params.slug}`);
return res.json();
}}
/>
</>
);
My client-side entry-point file client.js would be as below. It would hydrate the DOM on the browser side and also refer the above routes.js.
// Use hydrateRoot from `react-dom/client` to hydrate the DOM on the browser-side.
// Specify this file as client-side entry point within vite.config.js
// or webpack.client.js (depending on the bundler in use)
import { hydrateRoot } from "react-dom/client";
import { createBrowserRouter, RouterProvider } from "react-router-dom";
import { routes } from "./routes";
const router = createBrowserRouter(routes);
hydrateRoot(document.getElementById("root"), <RouterProvider router={router} />);
The above changes across all the pages and components within the frontend repository would ensure server-side rendering of the content. This would help early page discovery for crawlers and ensure the page HTML with content is indexed by all kinds of crawlers (those that render JavaScript content as well as those that do not).